

 David Mantica
David Mantica
The Quiet Promotion: Why Agentic AI Moves Your Role Upstream
The most frequent question I hear when I run sessions on agentic AI is some version of the same thing. "What does my role look like when this is...
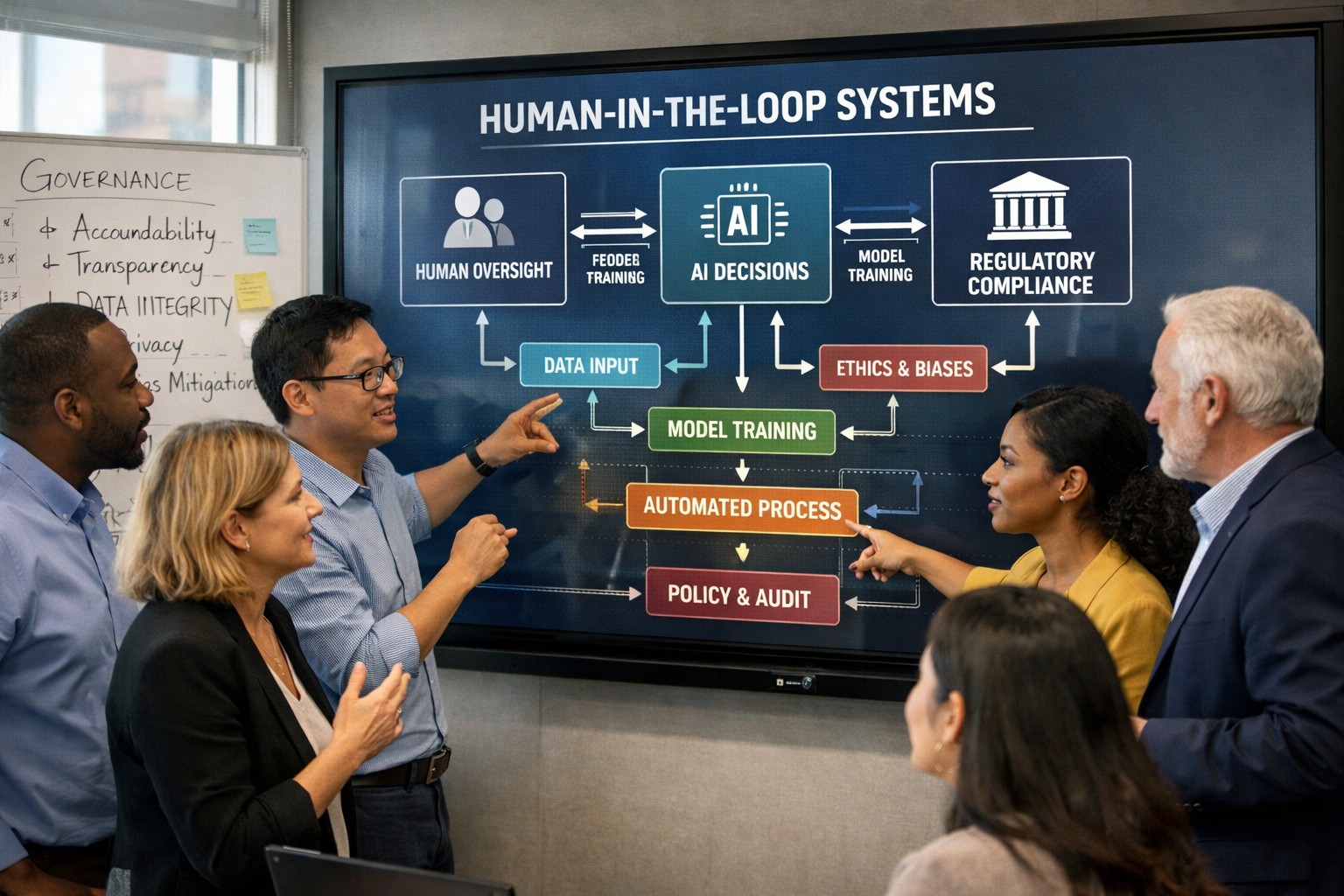

The most frequent question I hear when I run sessions on agentic AI is some version of the same thing. "What does my role look like when this is...

There is a new acronym you are going to hear constantly over the next eighteen months. It is MCP, and it stands for Model Context Protocol. If you...

If you are setting AI strategy for your organization in 2026, there is a piece of research you should read before you sign off on your next...