Safe to Fail and Formula 1
The term ‘Safe to Fail’ seems to be thrown about as if it is an easy thing to achieve.
It isn’t always safe to fail. Adam Boas put it beautifully at Agile Australia 2018 where he referred to “Defined Safe Boundaries over Motherhood statements about safe to fail”. (Boas, 2018)
So why do we need a safe to fail environment? As knowledge workers, we operate in the complex domain. The complex domain represents the "unknown unknowns". Here there are no completely defined answers and previous knowledge has limited applicability. The appropriate response, therefore, is to experiment, learn and respond to change as information emerges.
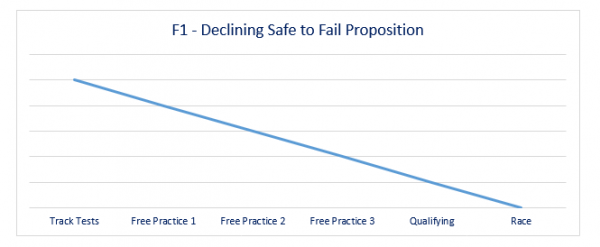
Consider safety to fail as a continuously declining proposition. Think, for example of a Formula 1 Motor Racing team. In Formula 1 there are three practice sessions, qualifying and then the race. Free practice 1 and 2 sessions are held the day before racing weekend, practice 3 is held hours before qualifying, and the race is on Sunday. Throughout the year there are testing days for the team.
During testing sessions, there are extensive programs of work that need to be completed for the team to understand if the changes they have made to the car have worked. Each new part is often switched in and out, effectively A/B testing. A driver will test the car to its limits, testing often to find these limits. The car may spin, parts may fail, or the driver may find the limit of their own talent; often the car is damaged as a result. At this stage, it is relatively ‘safe to fail’. Failure is not consequence-free however. The team will need to rebuild the car and depending on how much damage has occurred, this may take many hours. Often teams will work overnight during the testing cycle to ensure the maximum hours of on-road testing can occur. Everything prior to the track tests are a series of carefully considered hypotheses and are treated as such.
Fast forward to each race weekend and free practice 1 and 2 are again a relatively safe place to fail. The driver is seeking to find the limit of the car within the idiosyncrasies of the track in question. Free practice 3 is less safe to fail as if the driver puts the car into the wall, there is a very short turnaround time to prepare the car for the qualifying session. The qualifying session is critical and of course at this point, if the car is damaged during the session, then the position on the grid is affected. The race, of course, isn’t a safe to fail environment at all. Now of course drivers do make mistakes and incidents occur during all practice sessions, qualifying and even the race. The key differentiator is the impact. Drivers are more easily forgiven for mistakes during the practice sessions. Mistakes in qualifying and the race have much more significant impacts for the team and eventually for the driver. Make too many mistakes during these sessions and you will find yourself looking for a new drive.
So how do we relate this to software development? Henrik Kniberg refers to a ‘limited blast radius.’ (Kniberg, 2014). We are okay to make mistakes in order to learn however, we want to minimise the damage caused by these mistakes. “Failure without learning is simply, failure” (Kniberg, 2014).
The first step in understanding safe to fail is understanding that we are constantly hypothesis testing. We often go into projects with a blind leap of faith assumption that if we take a certain action, that then the following benefits will ensue. Scarily, in traditional approaches, we may find out somewhere along the line we are wrong, but we often don’t do anything about it. So many times, I have heard or been told, “we just have to do this”. We lose the why and the ability to question if we are right.
Here are a few simple steps to limit your ‘blast radius’:
1. Define the safe to fail boundaries
Experiments need to be small within a defined safe boundary. Some organisations will undertake Beta releases in markets such as New Zealand. New Zealand is small enough to conduct A/B testing on a change in a Production system but also small enough that if the change is considered a failure it can be rolled back with limited global impact. Effectively New Zealand may have a change applied, tested, failed and rolled back before people in Perth have even woken up. New Zealand companies might release in smaller markets again, such as Wellington.
2. Consider everything we do as a hypothesis
By resetting our mindset and considering all the work we do as a series of hypotheses, we move into a totally different paradigm. We aren’t always setting out to prove ourselves ‘right’. We are setting out of a search for truth. Designing and building a series of tests to assess these hypotheses sets the stage to allow us to determine if we should continue, pivot or stop at each stage of the experiment.
3. Test every hypothesis
Hypothesis-driven development requires testing for validation. We can test to see how a product or feature works, or more importantly whether it’s the right product for the user in the first place. We can then use this new knowledge to determine next steps. The goal of hypothesis testing isn’t; to prove the hypothesis is right, it is simply to learn – building knowledge and understanding to act or pivot as required.
4. Conduct simple testing using your peers
Don’t overlook a potential source of feedback that’s right at your fingertips. Feedback from your family, friends and colleagues who have our best interest at heart, can be both easy to garner, and incredibly valuable. You’ll find this form of feedback will be honest, unfiltered and be well-intended.
5. Make decisions based on data, never opinion.
In this data-driven era, we have access to copious amounts of data, but that data is only as good as the insight that we can draw from it. The need to make decisions in the complex environment is a clear indication of uncertainty – and where there is uncertainty, there is risk. Data can be used to decrease uncertainty and can help us to find patterns, predict and push forward.
Post by Julie Wilson
References:
Boas, A. (2018). People over Process. Melbourne: Agile Australia.
Kniberg, H. (2014, January). Spotify Agile Engineering Culture
Thank you!
Your details have been submitted and we will be in touch.
Thank you!
Your details have been submitted and we will be in touch.