Fail well – not just fast – for team and organisational learning
In August this year, I had the absolute pleasure of travelling to Nashville, Tennessee, to attend Agile 2013, the world’s largest gathering of Agile nerds enthusiasts and those well on their way!
Spanning a total of 4.5 days and 17 exciting tracks it’s needless to say that there were many outstanding sessions I was able to attend, and at least as many fabulous sessions I didn’t see, however, one of my favourites from this year was Jabe Bloom’s talk about “Failing well” (you can find more on and about Jabe Bloom on his blog on http://blog.jabebloom.com)
When I initially selected the session I was expecting some familiar wisdom about promoting accelerated failure in Agile teams to expedite learning, with a few valuable nuggets regarding useful metrics to gather and how to communicate the necessity and benefits of “failing fast” more clearly. However, what I got absolutely exceeded my expectations – at a rate of an idea a minute, Jabe Bloom threw ideas and concepts at the audience at lightning speed, leaving barely sufficient time to catch a breath in his 90-minute slot.
One main area the talk highlighted for me is the disproportionate focus on “failing FAST” which seems to have taken over the Agile community. Yes, failing as quickly as possible is highly beneficial insofar that it decreases the team’s and organisations’ exposure to risk, however we need to be careful to ensure that any experiment we have embarked on does not simply end with failure. In an attempt to make failure an acceptable and viable option in an organisation, the Agile community has positioned failure as an integral part of any development activity, especially in highly innovative environments, making it something to celebrate rather than something to avoid. Unfortunately, however, this is really only half the story – in order to make failure valuable (and therefore feasible within an organisational context), it needs to generate a large amount of information upon which a team can act in the future – knowing that “this one way didn’t work” is useful for ensuring we don’t repeat errors multiple times, but unfortunately it provides very little in terms of information for alternative action.
So not only do we have to ensure that we fail as fast as we can, we also have to keep an eye on the benefits we can draw from failure. While the temptation in any team or organisation is to “do more of what we know works” and “do less of what we know doesn’t work”, this strategy invites a concept called the “Competency Trap” (where individuals or organisations stick with a suboptimal process because the results are “good enough” and fail to improve in the long run) true learning and innovation comes from experimenting in the “grey area” where probability of failure is comparatively high but the insight gained provides real value for the team and/ or organisation.
The following diagram shows the correlation between asserted information (and therefore the probability of failure) and the value generated by experimentation and the resulting observations.
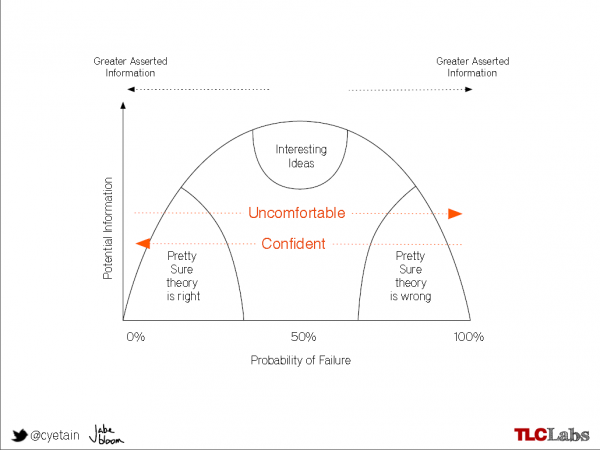
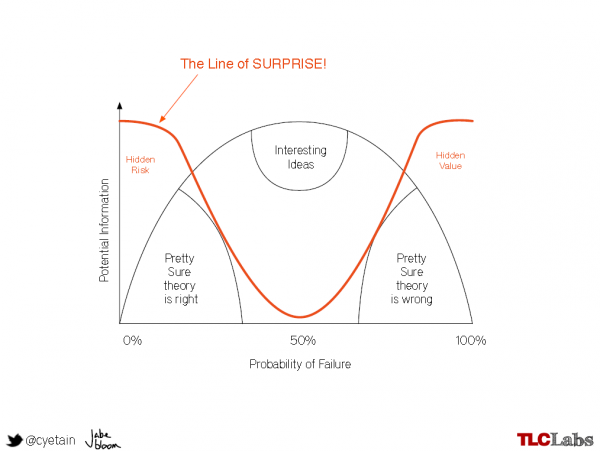
The “line of surprise” in the above diagram shows the areas in which failure, however unlikely, would provide high-value information due to the contrary positions of the knowledge asserted and the observation made. Finally, Bloom introduced the following extension to the diagram to show the correlation between the product development lifecycle and the use of experiments to generate information for learning:
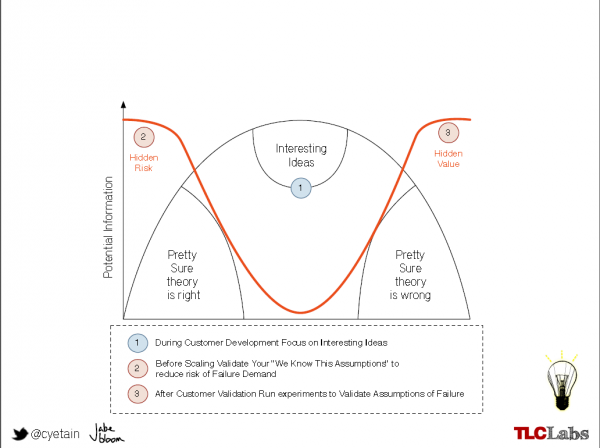
Randomness vs Known unknowns
At this stage, Bloom introduced the difference between alteaory (random) and epistemic (cognitive) uncertainty – while human error is alteaory, and therefore nonreducible, uncertainty relating to product development is epistemic – I may not know right now what will work / what I want / what the impact of a particular action will be but I can certainly learn more about it by validating or discarding assumptions. With this in mind, failure based on human error is as inevitable as it is limited in its usefulness in creating new learning – this is not to say that we cannot learn from human error but rather that, due to its random nature, we cannot induce it deliberately to validate or discard assumptions.
So when looking to create learning in an Agile team, we need to focus on epistemic uncertainties, i.e. the stuff that we don’t know much about but we could generate knowledge about by devising small, contained experiments and observing the outcomes. Now you might think “if the problem is cognitive, why don’t I get an expert in the field rather than trying to reinvent the wheel”? Excellent thought, often practiced – unfortunately not always with the best results, as J. Scott Armstrong discussed in his paper about the “Seer-Sucker Theory” (you can find the full paper on http://repository.upenn.edu/cgi/viewcontent.cgi?article=1010&context=marketing_papers). In a nutshell, this paper briefly outlines a variety of experiments in diverse fields ranging from stockbrokerage to clinical psychiatry which have shown that, past a certain degree of knowledge, increased expertise did not contribute to increased accuracy in forecasting outcomes – this phenomenon can be linked back to the human desire to validate our own beliefs and assumptions (what Jabe Bloom calls the “Vanity Validation”) enhanced by a seeming inability to cognitively map data which may disprove our beliefs or (assumed) knowledge – this means that people who are experts in a particular field (such as an agile software development team) are likely to be selective about the use and meaning of data generated by failure and biased towards the data confirming pre-existing beliefs, ignoring any contrary data.
Models of organisational learning
The next concepts Bloom introduced in his talk were Chris Argyris’ and Donald Schön’s models of “single-loop and double-loop learning”, where single-loop learning (SLL) describes a simple modification of actions to correct a result, while double-loop learning (DLL) requires the review and challenging of the underlying values, beliefs and goals (what Argyris and Schön call the “governing variables”) – or, in other words, SSL is about finding different ways to solve the problem while DLL is about rethinking, reshaping and rephrasing the problem (more on Chris Argyris’ work on organisational learning can be found on http://infed.org/mobi/chris-argyris-theories-of-action-double-loop-learning-and-organizational-learning/).
While there are benefits in both SSL and DLL, my experience is that many teams and organisations, single-loop learning reigns supreme and unfortunately the introduction of agile approaches has done little to shift this focus and many teams expend the vast majority of their efforts on “doing the thing right” rather than ensuring they’re “doing the right thing”.
Here’s Jabe’s diagram outlining the differences between SSL and DLL:
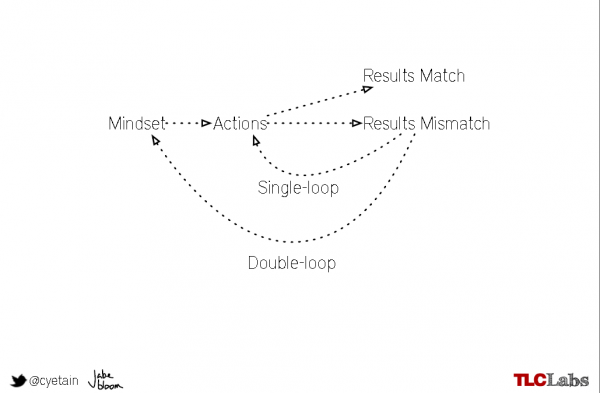
At this stage, well done for bearing with me and reading on – in case your head is spinning, here’s a quick summary of the key points:
- Failing “faster” is pointless if you don’t also fail “better”
- Understand the difference between random and cognitive uncertainty – focus on cognitive uncertainty rather than optimising against random events (such as a human error)
- Identify your own assumptions and conclusions
- Actively seek contrary data to overthrow your assumptions and conclusions to avoid “vanity validation”
- Understand when to correct your actions and when to challenge your governing variables
Using abductive reasoning to generate learning
While we have all heard of deductive logic and inductive reasoning, abductive reasoning tends to make less of an appearance. Better known as an “educated guess”, abductive reasoning is, in an organisational context, often the “last straw” we grasp at once we’re run out of other options. In his talk, Jabe Bloom argues that it should really be one of the first things we do. While deductive reasoning is binary (i.e. the conclusion is either right OR wrong) and inductive reasoning is about probability (i.e. the conclusion may be right or wrong), abductive reasoning is about what Bloom calls “justifiable plausibility”, meaning that this way of thinking does not leave you with a conclusion derived from either general statements or specific observations but rather what appears to be the most likely / plausible conclusion. While not an answer per se, this plausible conclusion can then form the basis of a hypothesis we can use to prove or disprove using a deliberate, small and contained experiment.
Multi-hypothesis research
Finally, Jabe Bloom introduced the concept of “multi-hypothesis research” to create hypotheses and design experiments in teams to generate valuable learning. He recommends NOT to brainstorm since this may invite convergent thinking too early – instead he proposes the selection of a team member to collect “just the facts” about a particular problem, without including theories, opinions or hypotheses at this stage. As a second step, identify any constraints and question the gathered facts thoroughly. Again, at this stage, there is no talking about ideas or potential solutions, only a thorough investigation of the validity of the facts collected earlier. This line of enquiry will not only help ensure that the facts are actually correct at this point in time but will also help the team to create a shared understanding of these facts before going off trying to identify solutions.
Now that the facts have been understood, split team members into pairs to investigate and discuss:
- What each team member would do to solve the problem (= hypothesis)
- What premises need to be fulfilled for each hypothesis to be true
- Experiments that would prove / disprove our hypothesizes
To ensure that the team looks at each hypothesis critically and from a variety of different angles, Bloom recommends that pairs are rotated several times before a final set of experiments against the created hypothesis is chosen for the team to implement and learn from.
The moral of the story
To sum up, “failing well” is at least as important as “failing fast” in the continuously evolving (and therefore, continuously learning) environment of software development – by creating multiple smaller experiments against multiple smaller abductive hypotheses for a single problem, teams can generate more information faster and by selecting the areas where failure is comparatively likely but the value of the information generated is high, we can build teams that can not only stumble upon but actually generate knowledge.
Posted by Shane Hastie
Thank you!
Your details have been submitted and we will be in touch.
Thank you!
Your details have been submitted and we will be in touch.